
multiprocessing max number of processes vs cores of CPU
I used to scrape web pages on my SDD, because I think saving files on SDD will be fater than on HDD, like many posts said. Recently, I have to save files on my HDD, because the SDD is full, and I feel the saving process is slower, but I have no idea how much it slower. Therefore, I designed a test script to compare the time consumed for saving files on SDD vs HDD. To conduct the test faster, I use the library multiprocessing. Many posts said the max number of processes should no bigger than the total number of CPU cores, but what will happen, if I set a bigger number of processes?
Here is the result:
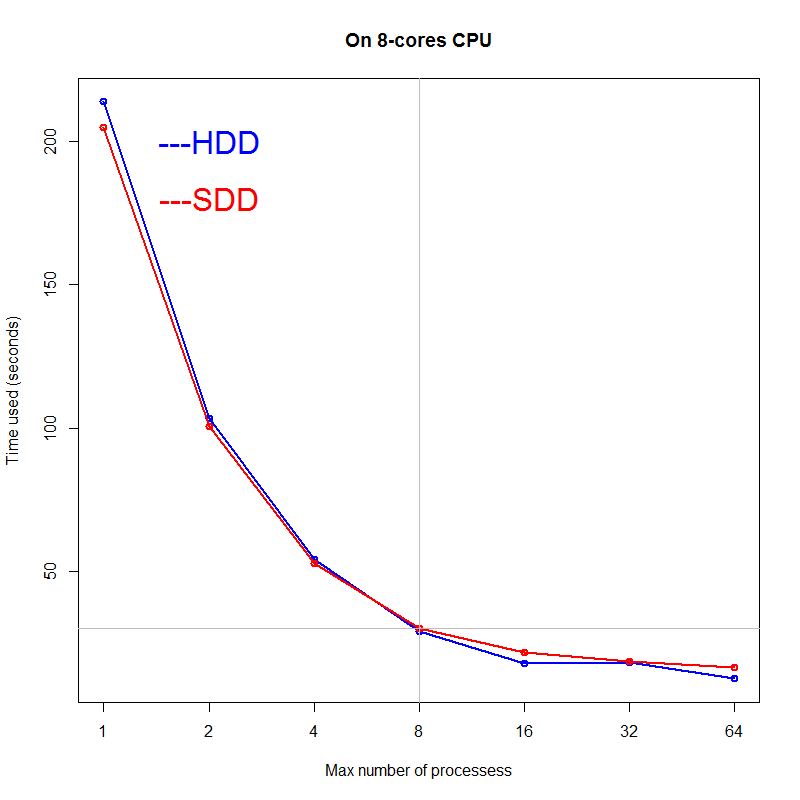
From above figure, we can say:
-
Time consuming of saving files on HDD is longer than on SDD when max number of processes smaller than the number of CPU cores, but faster when max number of processes bigger than the number of CPU cores (strange!).
-
Increase the max number of processes will always make the process faster, but the most efficient range are less than two times of the number of CPU cores. Therefore, set the max number of processes to 16 on a 8-core CPU will make sense.
-
The difference on HDD and SDD is not very big.
Here is the code of the test:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import time, re, sys, os, requests
from multiprocessing.dummy import Pool
def download_page(finn_code):
url = "https://m.finn.no/lookup.html?finnkode=" + str(finn_code)
try:
r = requests.get(url, timeout=5)
if r.status_code == 200:
html = r.content
with open(file_name, "w") as f:
f.write(html)
f.close()
#print finn_code + ": Downloaded!"
else:
pass
#print finn_code + ": Not Exists!"
except:
pass
#print finn_code + ": RequestError"
## download a url 1000 times.
codes = ['89014891'] * 1000
cpus = [1,2,4,6,8,10,12,14,16,32,64]
sdd = []
file_name = "/home/tian/Finn/test.html"
for n in cpus:
t1 = time.time()
pool = Pool(n)
pool.map(download_page, codes)
pool.close()
pool.join()
t2 = time.time()
tt = t2-t1
sdd.append(tt)
print "cpu number: " + str(n) + "; take seconds: " + str(tt)
file_name = "/home/tian/HDD1T/Finn/test.html"
hdd = []
for n in cpus:
t1 = time.time()
pool = Pool(n)
pool.map(download_page, codes)
pool.close()
pool.join()
t2 = time.time()
tt = t2-t1
hdd.append(tt)
print "cpu number: " + str(n) + "; take seconds: " + str(tt)
print sdd
print hdd