
Scrape dynamic web page (Google Group forum) using Selenium (1)
There are a lof of places to ask for help, e.g. StackOverflow, Google Groups, GitHub, etc. If you want to know who are the experts on a field or who are active on a field you can download all the questions and replies of one above places. The people ask a lot question in a period implies they are conducting a project in that field, and people replied most, seems to be experts on that field.
Scrape all the question and replies on StackOverflow and GitHub are straight: they are static web pages. But download Google Groups threads is a little headache. Take the Google Group: Shiny - Web Framework for R as an example: if you open the web page, you can see only 31 topics, while there are more than 5700 topics in total. Then you scroll the page down, 30 more topics loaded, and keeping scroll down, more topics are loading. But, will you scroll down to the bottom to load all topics? I will not.
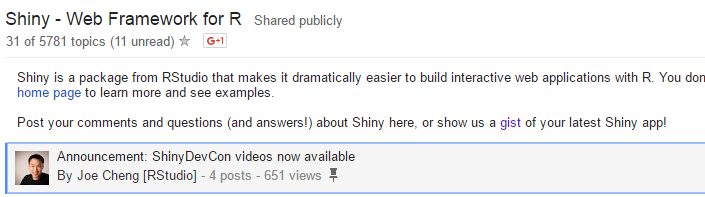
Now, we need Selenium (python package request may also take the job, I will explore it later). Each topic has a unique href to special page, where stores the question and all replies. We need to find all href of the topics in order to download all topics pages.
The most difficult task is how we get all href. We need Selenium can scroll down the page automatically. If you google “Selenium phython scroll down to the bottom”, you can easily find the page.
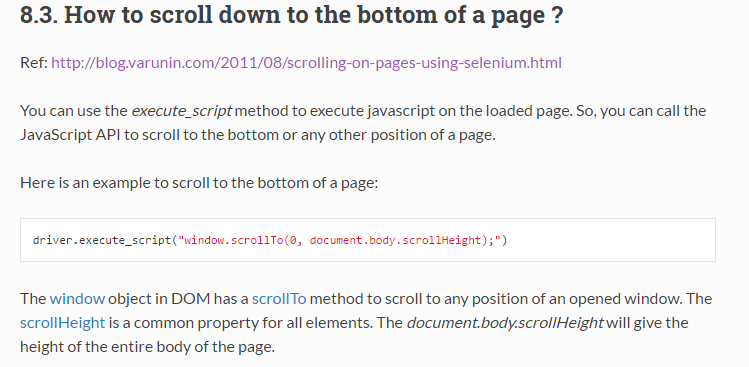
However, this method doesn’t work for our task. That’s because the page has loaded and shown completely, what should be scrolled is the topic table, once you scroll down to its bottom, new topics will be loaded. By searching a lot, I found the following command works:
document.getElementById("the id of last element in the table").focus()
Now the problem changed to: how can we find the last element? Well, Selenium has various strategies to find elements in a page. As we need to find the last element, so it’s better to use the method: find_element_by_xpath
topic_last = browser.find_elements_by_xpath("(//tbody/*//a[contains(@href, '#!topic')])[last()]")[0]
id1 = topic_last.get_attribute('id');
Now, the most important tasks seem have all solution: we can find the last topic, and let selenium to scroll down to that topic so the page will load new topics, so we can extract more href. Yes, and no. After fixing the above two tasks, I spend times of the time to get the scraping task done, the main problem is we have to find a balance between the quickness and completeness, together with how to handle exception, error log and monitor progress.
In short:
1: Quickness and completeness To load 30 new topics the browser generally need more than 1 second, but no more than two seconds. So, I set the waiting time to 2 seconds. However, some times, the loading process may take more than 5 seconds. For this situation, we should wait or try to load topics again.
2: Download exception When download a topic’s web page, we may encouter some problem, like the server response slower, if so, then we need to download again, however if we tried several times, but still can’t download, then we should save the undownloaded page into log file, and keeping download others.
3: Monitor progress We need to include some codes to show how many topics/percentage downloaded, if encounter some error, we should also pop-up it.
Here is the full code to download the shiny Google Group topics in python:
from pyvirtualdisplay import Display
from selenium import webdriver
from bs4 import BeautifulSoup as BS
import time, re, sys
## Note: include ?hl=en make sure the page display language is English, otherwise will be the system default language.
gg = 'https://groups.google.com/forum/?hl=en#!forum/shiny-discuss'
wd = "/home/tian/shinyExpert/"
display = Display(visible=0, size=(1920, 1080)).start()
browser = webdriver.Firefox()
browser.get(gg)
time.sleep(2)
print browser.title.encode('utf8', 'replace')
n = 0;
t0 = time.time();
topic_last = browser.find_elements_by_xpath("(//tbody/*//a[contains(@href, '#!topic')])[last()]")[0]
id1 = topic_last.get_attribute('id');
while True:
js = 'document.getElementById("' + id1 + '").focus()'
browser.execute_script(js)
time.sleep(2+n/100)
t1 = time.time()
topic_last = browser.find_elements_by_xpath("(//tbody/*//a[contains(@href, '#!topic')])[last()]")[0]
id2 = topic_last.get_attribute('id')
if (id1 != id2):
n = n + 1
id1 = id2
msg = "\rLoad: " + str(n) + " times; Used seconds:" + str(round(time.time()- t1, 3))
sys.stdout.write(msg);sys.stdout.flush()
else:
time.sleep(2)
topic_last = browser.find_elements_by_xpath("(//tbody/*//a[contains(@href, '#!topic')])[last()]")[0]
id2 = topic_last.get_attribute('id')
if (id1 != id2):
n = n + 1
id1 = id2
print "\nReload! " + str(n) + " times; Used seconds:" + str(round(time.time()- t1, 3))
else:
print "\nAll content loaded!"
break
with open(wd + 'forum.html', "a") as f:
f.write(browser.page_source.encode('utf8', 'replace'))
f.close()
print '\nTotal scraping used: ' + str(round(time.time()- t0)) + ' seconds!'
N = len(browser.find_elements_by_xpath("//tbody/tr/*//a[contains(@href, '#!topic')]"))
print 'Total threads: ' + str(N)
bs = BS(open("/home/tian/shinyExpert/forum.html").read())
HREF = bs.findAll("a", {"class": "IVILX2C-p-Q"})
N = len(HREF)
for n in range(0, N):
if (n % 500 == 0):
browser = webdriver.Firefox(); time.sleep(1)
print '\nBrowser cache cleaned!'
href = HREF[n].get('href')
url = re.sub('#!.*$', href, gg)
try:
browser.get(url)
time.sleep(2)
divs = browser.find_elements_by_xpath("//div[@class='IVILX2C-tb-x']")
if (len(divs) == 0):
browser.get(url)
time.sleep(10)
divs = browser.find_elements_by_xpath("//div[@class='IVILX2C-tb-x']")
print "\nLength of divs equal 0! After 10 seconds, length of divs equal: " + str(len(divs))
if (len(divs) == 0):
with open(wd + 'log_download.txt', "w") as log:
log.write(url + "\n")
log.close()
else:
time.sleep(1)
## file_name = time.strftime("%Y%m%d_%H%M%S_")
file_name = '{:04d}'.format(n+1) + re.sub('^.*/', '_', href)
with open(wd + 'topics/' + file_name, "a") as f:
f.write(browser.page_source.encode('utf8', 'replace'))
f.close()
msg = "\rIndex: " + str(n) + "; file: "+ file_name
sys.stdout.write(msg); sys.stdout.flush()
except:
print "\nBrowser fail to get: " + href